Context:
Currently, when we apply an ES bucket limit we do not limit the overall number of buckets but just the number of buckets on groupBy/distributedBy level separately. This leads to two issues:
- The biggest issue is that in practice, we could still end up with too many buckets, depending on how may distributedBy "sub buckets" the result has.
- some distributedBys (userTask,flowNode) are finite and known through the bpmnModel there we could easily control by limiting through the groupByBuckets
- other distributeBys are unbounded though (variableValue,assignee) these are more challenging to limit as we may have to determine the expected bucketCount for the distributedBy
- When we complete the result with "missing" distributed by keys (see `enrichContextWithAllExpectedDistributedByKeys`), depending on the sorting, we might end up with only these empty "filler" distributedBy results even when "real" results are present. This is because in order to find all expected distributedBy keys, we simply add a sibling distributedBy aggregation on groupBy level which is also unaffected by the ES bucket limit.
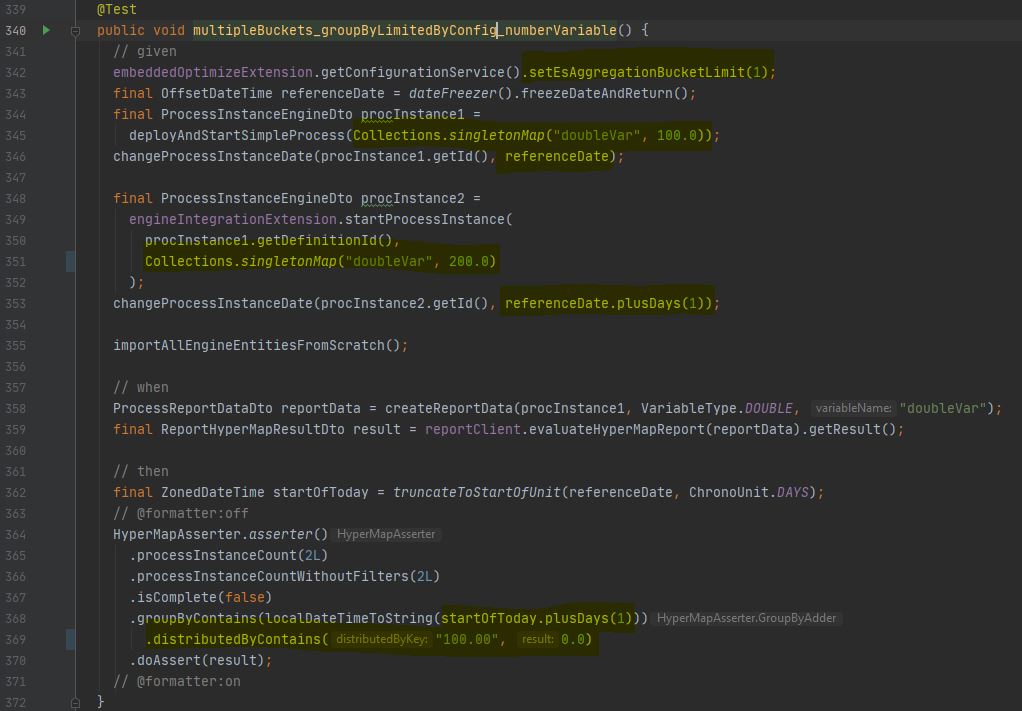
An example to illustrate 2.) is attached as a screenshot. In the attached (passing) test case an instance frequency by instance date by variable report is built. It would be preferable to return a result with the only distributedBy bucket being "200.0" (and a value of 1.0) instead of the empty 100.0 bucket (line 369).
AT:
- A solution is found to solve the above issues. Ideally, the ES bucket limit applies to the overall amount of buckets
- IT is added to cover proper distributedBy bucket limitation