Description
Brief summary of the bug. What is it ? Where is it ?
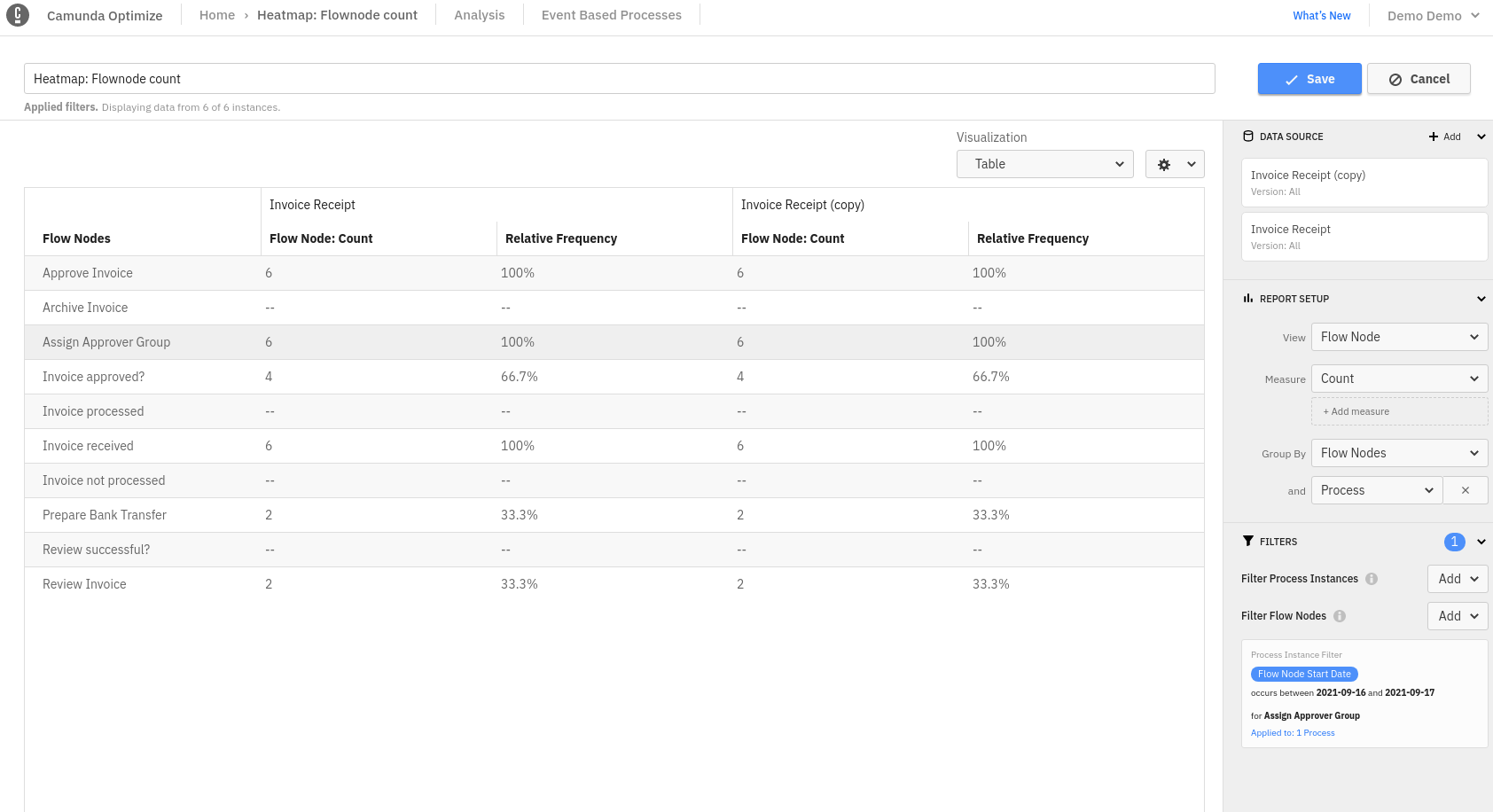
Process specific filters have no effect on the process/datasource assigned to given another process/datasource includes the same process instances. For example:
- Create a report Flow Node Count By Flow Nodes
- Change the definition version to all
- Add a filter that configure it so that no instances are in the result (e.g. a Process Instance Filter for a Flow Node Start date in the future)
- Duplicate the data source/process so that they have "overlapping" data
- Add secondary grouping by process
Actual result :
The result contains the same counts (>0) for both processes
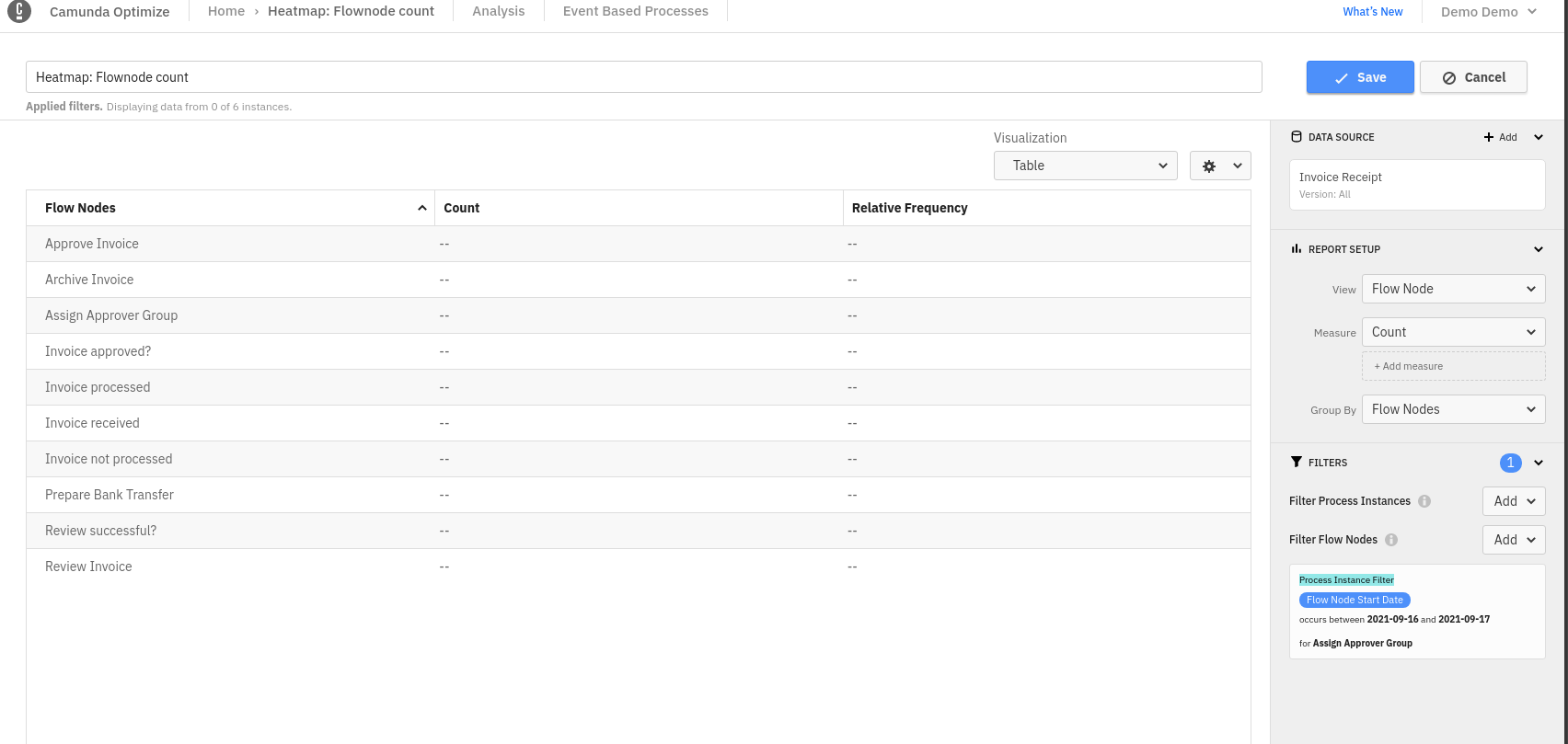
Expected result:
The result should only contain count >0 for the process to which no filters are applied
Hint:
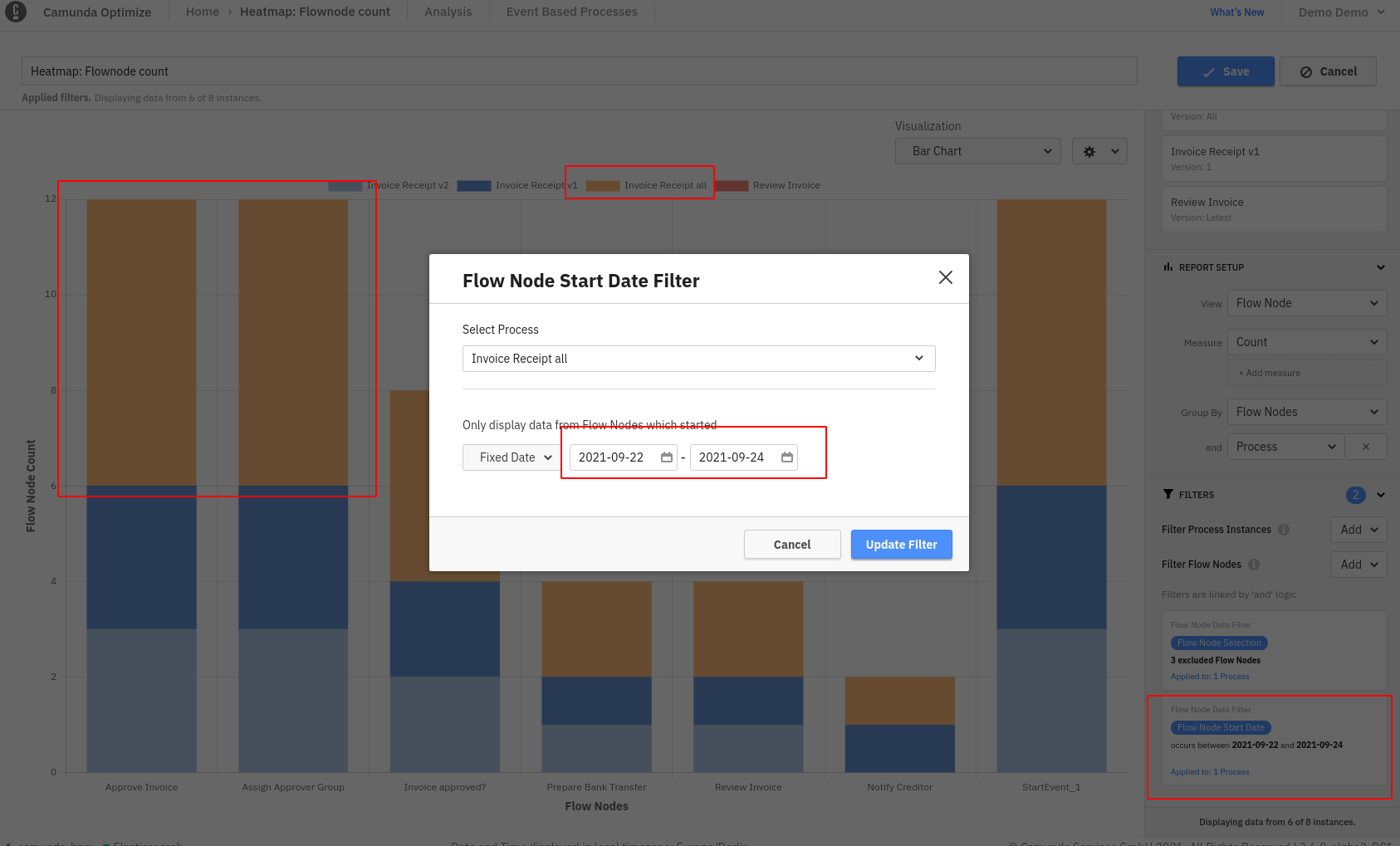
The flow nodes that form the aggregation are sourced from the "should" query across all data sources (processes). Therefore, if one filter removes the flow nodes but they are still included from another data source, they will still appear in the result and still get merged upon result retrieval during the process distribution. To handle this better, we would need to either:
- Perform separate queries for each data source rather than merge from the results
- Refactor our query building so that aggregation trees are independent for each source and the filter is applied accordingly