-
Type:
Bug Report
-
Resolution: Unresolved
-
Priority:
 L3 - Default
L3 - Default
-
None
-
Affects Version/s: None
-
Component/s: backend
-
2
-
S
-
2 - Flawed
Brief summary of the bug. What is it ? Where is it ?
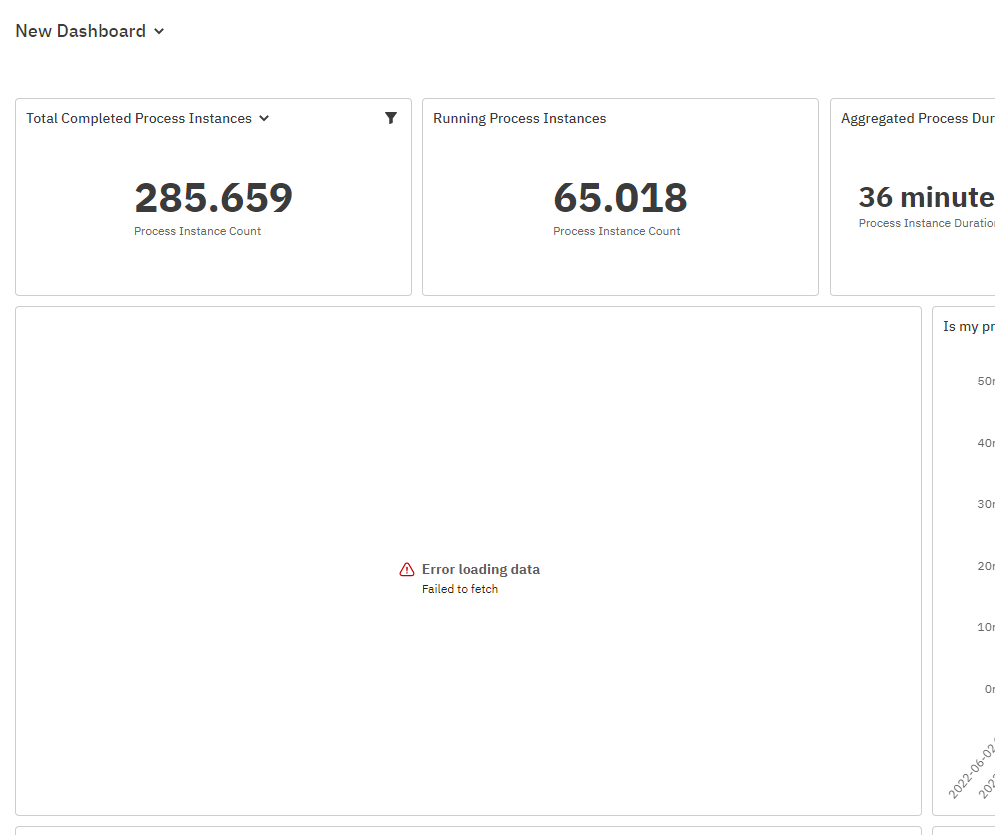
When having millions of process instances of the same process definition, the following reports in the "Process performance overview" dashboard utilize (almost) all Elasticsearch's resources:
- Is my process within control?
- Which process steps take too much time? (To Do: Add Target values for these process steps)
For example
- When having ~2.4m process instances, each corresponding search/aggregation request takes roughly ~12 minutes to execute
- When having ~5.6m process instances, each corresponding search/aggregation request takes roughly ~30 minutes and longer to execute (I canceled the queries in Elasticsearch after 30 minutes)
As a consequence, these search requests occupy most of Elastic's search threads. In the Cluster Plan G3-S, Elastic's search thread pool has a maximum of 4 threads. So, two of the threads are busy with these requests and all other search requests are handled by the left free threads. That way, other search requests are piling in the thread pool's queue and everything gets slower.
This impacts the other Camunda 8 components as follows:
- In Operate most of the requests are timing out.
- The importers are standing still as the search requests are getting slower and slower. That way, the importers start to lag behind for some minutes (but they recover once the occupied resources are freed up)
- ...
Giving Elastic more resources reduces the impact only a bit, but these search requests still take a lot of time to execute, and the importers are still suffering as long as the search requests are in progress.
Steps to reproduce:
- Create cluster with Cluster Plan G3-S
- Start 5 PI/s of the typical process
- Wait roughly ~1 week until there are 2.4m (mostly completed) process instances in the system
- Create a "Process performance overview" dashboard
- Open the dashboard
Actual result:
- The reports are timing out
- Other components (like Operate) are getting time-outs as well.
- The importer starts to lag behind for that period of time.
Expected result:
- If it is possible to catch time-outs in the backend, then the backend should cancel the corresponding search task in Elasticsearch. That way, Elasticsearch would be able to release the resources earlier (and not only when it completes), and the impact on other components would be mitigated.
- Best solution would be if the reports do not time-out
{kind=link}