-
Type:
Bug Report
-
Resolution: Unresolved
-
Priority:
 L3 - Default
L3 - Default
-
None
-
Affects Version/s: None
-
Component/s: None
-
None
-
Not defined
Brief summary of the bug. What is it? Where is it?
Whenever a (text/string) variable is imported in Optimize, it applies the ngram_tokenizer to the variable value. Basically, it breaks down the text into words of 1 char up to 10 chars. For example, the text abcdefghijklmn is broken down into:
[a, ab, abc, abcd, abcde, abcdef, abcdefg, abcdefgh, abcdefghi, abcdefghij, b, bc, bcd, ...]
When the (text/string) variable has a size of ~1MB, which gets tokenized accordingly, then this may result in high memory utilization, causing Elasticsearch to fail with OOM (depending on the resource limits).
Steps to reproduce:
1. Create a new cluster in C8 SaaS by choosing the lowest cluster plan G3-S (which currently comes with 2GiB Memory for Elasticsearch)
2. Start the big variable client which starts after 5 minutes a process instance with a big variable (~1MB)
Actual result:
When the Optimize's importer submits the UpdateRequest to add the variable to the process instance, Elasticsearch terminates caused by OOM.
2022-08-23 05:55:27.403 CEST [gc][398] overhead, spent [429ms] collecting in the last [1s] 2022-08-23 05:55:29.513 CEST java.lang.OutOfMemoryError: Java heap space 2022-08-23 05:55:29.513 CEST Dumping heap to data/java_pid8.hprof ... 2022-08-23 05:55:29.514 CEST [gc][400] overhead, spent [592ms] collecting in the last [1.1s] 2022-08-23 05:55:32.332 CEST Heap dump file created [997300945 bytes in 2.819 secs] 2022-08-23 05:55:32.332 CEST Terminating due to java.lang.OutOfMemoryError: Java heap space
While tokenizing the big variable, memory consumption grows in Elasticsearch. Basically, Elasticsearch creates 32kb blocks containing the tokens. Before going out of memory, Elasticsearch tokenized roughly half of the big variable, resulting in ~5000 blocks * 32kb = 166MB memory utilization. And in total, to process the update request in Elasticsearch, it consumed ~225MB.
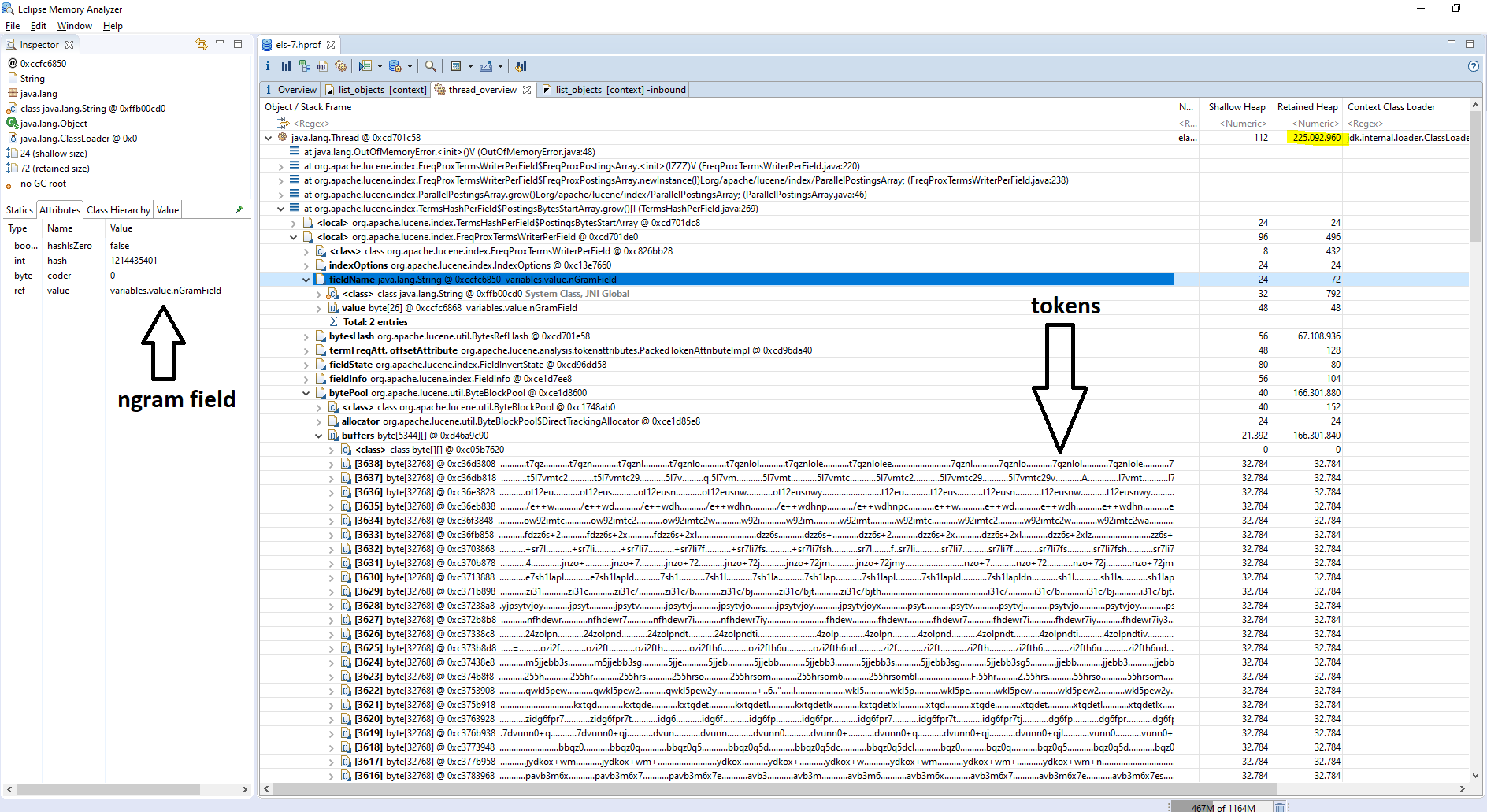
For reference, the JVM heap dump can be downloaded here
Expected result:
- Elasticsearch doesn't fail with OOM
Possible Solutions
- Increase Elasticsearch hardware resources to process the update request successfully (but still then it would still materialize in high disk space usage)
- Don't tokenize big variables (e.g., with more than 7k chars)
- Tokenize only the first 1000 chars, for example
- Decrease the ngram_max to 5 so that it will result in roughly half of the memory utilization
Please note: Changing the tokenizer settings may change the user experience.
- is related to
-
OPT-4052 Speedup the wildcard query search for variable values and variable string filters
-
- Open
-
- links to