There are a number of failures that are based on outdated process instance state and that are detected on database-level via constraint violations (e.g. foreign key violations or uniqueness violations). The correct way for users to deal with these situations is retrying the interaction (like in cases when OptimisticLockingException is thrown).
Current behavior:
- The process engine throws ProcessEnginePersistenceException. For such exceptions, users cannot distinguish the optimistic locking case from the case where something is seriously broken. Thus, they cannot perform automated retries.
Expected behavior:
- The process engine throws OptimisticLockingException so that users can always catch the exception and retry the interaction.
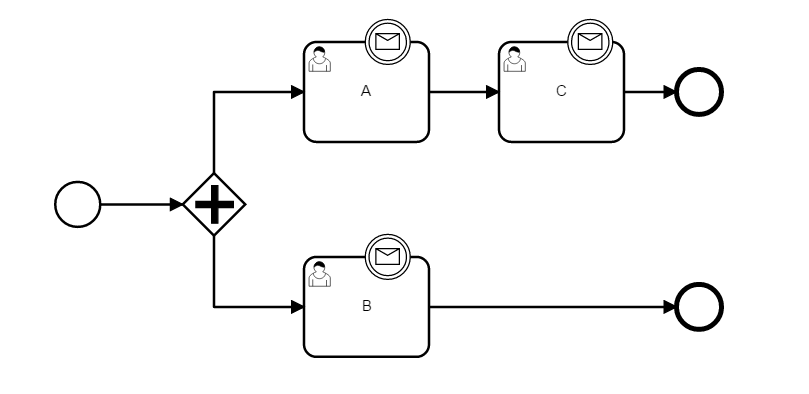
Example 1:
- See the attached BPMN model, no async continuations
- Tasks A and B are active, expanded execution tree
- Two parallel transactions complete each of the tasks, in an interleaved fashion
- TX1 (completing A) and TX2 (completing B) both fetch the execution tree
- TX2 completes, triggering tree compaction
- TX1 completes, deletes A's scope execution and creates a new scope execution for C
- Since TX1 still works on the expanded tree, it INSERTs a new execution as a child of a concurrent execution. This concurrent execution does not exist anymore in the database, so the INSERT fails with a constraint violation.
Example 2:
- violation of uniqueness constraint of scope and name of variables (i.e. no scope can have the same variable twice)
Basic solution ideas:
- Reordering the flush when there are dependencies between entities (in example 1: currently, the UPDATE of the concurrent execution is performed after the INSERT, so the UPDATE does not trigger OptimisticLockingException. Reversing the order would avoid the constraint violation).
- Catching java.sql.SQLIntegrityConstraintViolationException on INSERT and then re-selecting any foreign-key-referenced entities to check their existance. If they don't exist anymore, throw OptimisticLockingException
- depends on
-
CAM-8759 Change isolation level to READ-COMMITTED for MySQL containers
-

- Closed
-
- is related to
-
CAM-6468 CompetingMessageCorrelationTest breaks when running on MySQL/MariaDB with READ_COMMITTED transaction isolation level
-
- Closed
-
-
-
- Closed
-