Scenario:
- Oracle
- ~ 1,000,000 jobs (whereby > 90% are timer jobs)
- on average ~ 10 jobs are due when the job acquistion query runs
Problem:
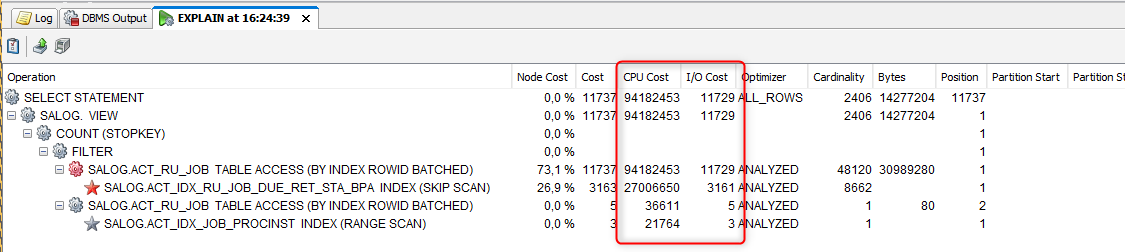
- The job acquistion query performs a full table scan to get 3 jobs to execute. This results in a slow query and high CPU utilization

- An index on column DUEDATE_ does not have any impact, because the job acquisition query does a null check (see RES.DUEDATE_ is null)
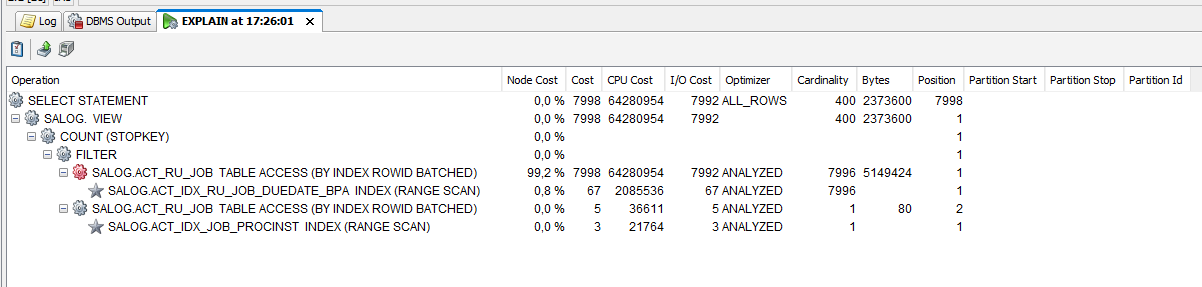
- A composite index like (RETRIES_, SUSPENSION_STATE_, DUEDATE_) can be used by the optimizer to execute a index skip scan operation, which reduces the overall costs, but the CPU utilization is still quite high.


How to improve the (CPU) costs?
- Get rid of the null check (i.e. RES.DUEDATE_ is null)
- For each created job a due date should be applied (in case of non-timer jobs it should be the current timestamp)
- This should be configurable.
What is the result of the improvement?
- The index on DUEDATE_ or the composite index (RETRIES_, SUSPENSION_STATE_, DUEDATE_) can be used to run the job acquisition query.
- Instead of an index skip scan an index range scan is executed. The index range scan is less expensive than the index skip scan.
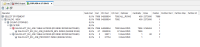

- The operation table access by ROWID (batched) still results in a high CPU consumption. So that the overall costs are still high. A high clustering factor (of the indexes) relative to the number of leaf blocks may increase the number of data blocks required to satisfy a range query based on the indexed column.
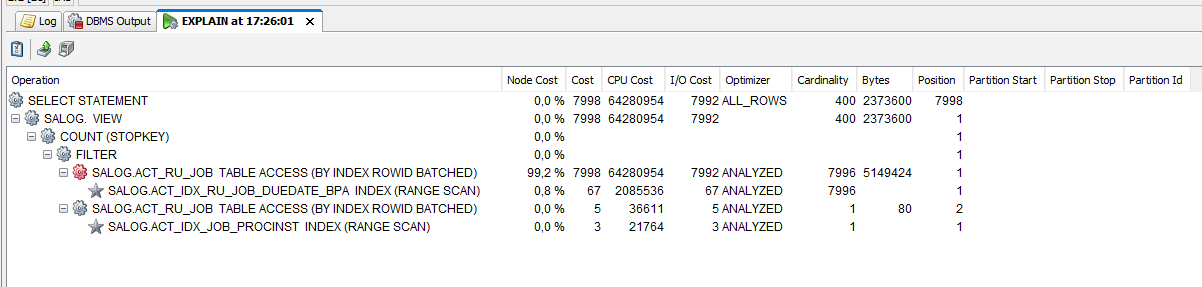

Hint:
- This report is based on "experimental" evidence.
- The CPU costs of the query will most likely remain high.