-
Type:
Feature Request
-
Resolution: Fixed
-
Priority:
 L3 - Default
L3 - Default
-
Affects Version/s: None
-
Component/s: None
User Problem:
Context:
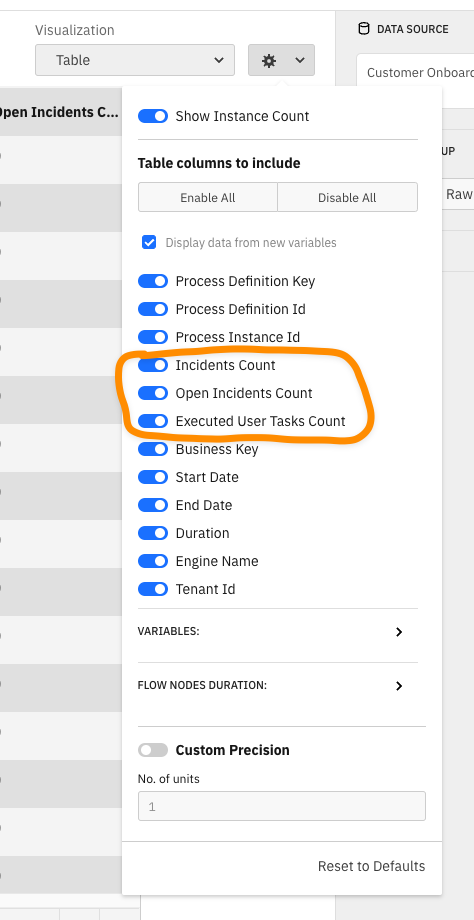
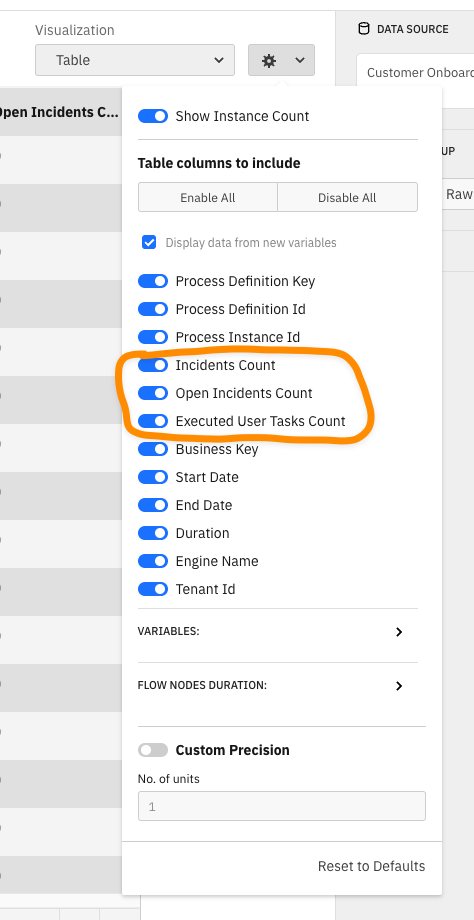
- The raw data report allows the configuration of columns included in the report.
- For the Machine Learning User Case, we added additional columns (e.g. Count)
Problem:
- The UX to disable NOT needed fields, e.g. if you are NOT doing Machine Learning, is time-consuming.
User Story:
- As a user of Optimize, I would like to have an improved way to exclude a certain columns from the raw data report. This allows me to build a report more quickly.
Solution Ideas
- Group all "count columns" in a group called "Counts" similar to the grouping of variables
- Set the default status for all columns included in collapsed groups to "disabled" (this is not done, see the comment below). This results in the default report only containing the main process columns that are not grouped by "Counts" / "Variables" / "Flow Node Duration"
Testing Notes:
the columns Incidents Count, Open Incidents Count and Executed User Tasks Count are now grouped together into counts group and column names are now called: Count: incidents, Count: openIncidents and Count: userTasks.
In the report configuration popover (when you click on the cog button in top right) there is new collapsible section called Counts which groups the incidents, openIncidents and userTasks together
All the functionalities like column rearrangement and disabling columns should work as before